
JS八股文
JS也有八股文,有一些也是必考的,所以在这里做一个记录。
参考链接1:前端代码题1 | Yle (yleave.top)
参考链接2:mqyqingfeng/Blog: 冴羽写博客的地方
1、防抖
频繁的事件触发,比如
- window的
resize、scroll mousedown、mousemovekey、keydown
防抖的原理就是:你尽管触发事件,但是我一定在事件触发 n 秒后才执行,如果你在一个事件触发的 n 秒内又触发了这个事件,那我就以新事件的时间重新开始计时,n 秒后才执行,总之,就是要等你触发完事件 n 秒内不再触发事件,我才执行。
定时器
第一版防抖,使用一个定时器,只有定时器到了才会执行函数,每次被重新激活,就取消之前的延迟调用的定时器。这种方式实现的防抖函数被称作延迟执行的防抖函数。
function debounce(fn, wait) {
let timeout = null;
return function () {
// 每当用户输入的时候把前一个 setTimeout clear 掉
clearTimeout(timeout);
// 然后又创建一个新的 setTimeout, 这样就能保证输入字符后的 interval 间隔内如果还有字符输入的话,就不会执行 fn 函数
timeout = setTimeout(() => {
// this 确保当前指向的对象是调用函数的对象,如 input 对象
fn.apply(this, arguments);
}, wait);
};
}
第二版防抖,需要立刻执行函数,而不是定时器到了才会执行函数,只有停止n秒,才可以重新触发。使用一个immediate参数来表现是否立即生效。只有在time为null的时候才立马执行fn函数。
function immedDebounce(fn, wait, immediate) {
let timeout = null;
return function () {
if (timeout) clearTimeout(timeout);
if (immediate) {
if (timeout == null) {
fn.apply(this, arguments);
}
timeout = setTimeout(() => {
timeout = null;
}, wait);
} else {
timeout = setTimeout(fn.apply(this, arguments), wait);
}
};
}
后续的也扎不多了,有返回值和取消的,这两个都比较简单,返回么只能在immediate为true的时候才能返回值,如果为false那么本身就是异步执行的,不能返回值。如果取消,添加一个按钮,clearTimeout,并且把timeout置为null就行了。
时间戳
除了定时器,还能时间戳的方法,这个比较直观,而且都是同步的方法,比起异步不知道高到哪里去了。
function debounce(fn, wait) {
let activeTime = 0;
return function () {
const now = +new Date();
// 若已等待了 wait 毫秒,则能重新触发
if (now - activeTime >= wait) {
fn.apply(this, arguments);
}
activeTime = now;
};
}
2、节流
节流的原理很简单:如果你持续触发事件,每隔一段时间,只执行一次事件。
节流和防抖的区别:防抖如果多次重新触发,那么就会以最后一次触发又开始重新计时,所以用户一直动,就永远不会触发下一次。但是节流,是n秒内执行一次,n秒过去了,就可以执行下一次,所以用户一直动也没关系,只要n秒过去了,那么就可以执行下一次了。
根据首次是否执行以及结束后是否执行,效果有所不同,实现的方式也有所不同。
我们用 leading 代表首次是否执行,trailing 代表结束后是否再执行一次。
关于节流的实现,有两种主流的实现方式,一种是使用时间戳,一种是设置定时器。
时间戳
下面这个时间戳和节流的方法看起来很像,区别就是把activeTime挪到了if语句里面,不用每次触发都重新计时,而是超过了规定wait时间,就能够重新触发。头执行方式。
function throttle(fn, wait) {
let activeTime = 0;
return function () {
const now = +new Date();
// 若已等待了 wait 毫秒,则能重新触发
if (now - activeTime >= wait) {
fn.apply(this, arguments);
activeTime = now;
}
};
}
定时器
头执行的定时器
function throttle(fn, wait) {
let timeout;
return function () {
if (!timeout) {
fn.apply(this, arguments);
timeout = setTimeout(function () {
timeout = null;
}, wait);
}
};
}
尾执行的定时器方法,只有定时器到点了才执行。
function throttle(fn, wait) {
let timeout;
return function () {
if (!timeout) {
timeout = setTimeout(function () {
timeout = null;
fn.apply(this, arguments);
}, wait);
}
};
}
2.5、setTimeout 模拟 setInterval
copy 为什么要用 setTimeout 模拟 setInterval ? - HelloWorld开发者社区
因为setInterval是尾执行的,所以需要在setTimeout里面执行,然后再循环调用自己,返回clear函数就行了。
function interval(fn, wait) {
let timer;
function inner() {
timer = setTimeout(function () {
fn.call(null);
inner();
}, wait);
}
function clear() {
clearTimeout(timer)
}
inner();
return clear;
}
3、数组去重
直接上ES6方法,用set方法去重
function unique(arr) {
return Array.from(new Set(arr));
}
或者一句话
const unique = (arr) => [...new Set(arr)];
好,本节结束(bushi)
用indexOf来反复查找res,看看添加进去的有没有重复
function unique(arr) {
const res = [];
for (let i of arr) {
if (res.indexOf(i) === -1) {
res.push(i);
}
}
return res;
}
或者用filter
arr1 = arr.filter((val, idx) => {
return arr.indexOf(val) === idx;
});
或者用es6方法,includes,毕竟不需要获得查找到的下标
function unique(arr) {
const res = [];
for (let i of arr) {
if (!res.includes(i)) {
res.push(i);
}
}
return res;
}
排序数组,然后比较前一个和后一个
function unique(arr) {
if (arr.length == 0) return [];
const sortArr = arr.slice().sort();
const res = [sortArr[0]];
for (let i = 1; i < sortArr.length; i++) {
if (sortArr[i] === sortArr[i - 1]) continue;
else res.push(sortArr[i]);
}
return res;
}
4、深拷贝和浅拷贝
经典中的经典
浅拷贝
Object.assign()
const obj2 = Object.assign({}, obj);
展开运算符
const obj2 = { ...obj };
数组浅拷贝
slice(),concat()和Array.from()都是浅拷贝,都会拷贝原数组的第一层,返回一个新的数组
循环遍历浅拷贝
const shallowCopy = function (obj) {
// 如果不是对象的话,直接返回
if (typeof obj !== 'object') return;
// 根据obj的类型判断是新建一个数组还是对象
const newObj = obj instanceof Array ? [] : {};
// 遍历Object.entries,此方法不会遍历原型链上的属性
for (let [key, value] of Object.entries(obj)) {
newObj[key] = value;
}
return newObj;
};
深拷贝
如果遇到复杂对象,可以使用工具库,比如 lodash 的 cloneDeep 方法。
一般深拷贝,使用万能的JSON方法,真的牛皮。
var new_arr = JSON.parse(JSON.stringify(arr) );
缺点:只适用于Number、String、Boolean、Array和扁平的对象,也就是说能够转换成JSON格式的都可以这么用。
undefined、任意的函数、symbol 这些不能转换成JSON对象就不行,此外特殊的对象如 RegExp、Date、Set、Map 等也无法使用这个方法进行深拷贝。
抄过来的稍微完备版本的深拷贝
- 使用了
WeakMap解决了循环引用问题,且不会造成内存泄漏。 - 能应对
RegExp、Date、Function、Map、Set等特殊对象的拷贝。
function deepClone(obj, map = new WeakMap()) {
// 处理 null 和 undefined
if (obj == null) return obj;
// 若是基本类型,直接返回
if (typeof obj !== 'object' && typeof obj !== 'function') return obj;
// 处理 Date 和 RegExp
if (obj instanceof Date) return new Date(obj);
if (obj instanceof RegExp) return new RegExp(obj.source, obj.flags);
// 使用 map 解决循环引用问题
if (map.has(obj)) return map.get(obj);
// 处理函数对象 返回一个新函数,在调用这个函数时会返回原本函数的执行结果
if (obj instanceof Function) {
return function () {
return obj.apply(this, [...arguments]);
};
}
// 下面是 数组/普通对象/Set/Map 的处理
// 从其原型链中继承的 constructor
const res = new obj.constructor();
// 设置 map 以处理循环引用问题
map.set(obj, res);
if (obj instanceof Map) {
obj.forEach((item, index) => {
// index 不一定是基本数据类型
res.set(deepClone(index, map), deepClone(item, map));
});
} else if (obj instanceof Set) {
obj.forEach((item) => {
res.add(deepClone(item, map));
});
} else {
// 使用 Object.entries 不需要再使用 hasOwnProperty 来验证是否是自身属性
for (let [key, value] of Object.entries(obj)) {
if (value && typeof value === 'object') {
res[key] = deepClone(value, map);
} else {
res[key] = value;
}
}
}
return res;
}
5、柯里化
柯里化是函数式编程中的一个重要概念,它是一种将使用多个参数的函数转换成一系列使用一个参数的函数的技术。为了保证柯里化能达到预期效果,这个函数需要是纯函数。
好处:减少代码冗余、增加可读性
坏处:若参数过多难免对性能造成一定影响
这样理解柯里化 :用闭包把参数保存起来,当参数的数量足够执行函数了,就开始执行函数
柯里化的函数实现如下,抽象
function curry(fn, args = []) {
return function () {
let newArgs = args.concat(Array.from(arguments));
// 每次调用时判断此时的参数是否足够,从而选择要调用 fn 还是继续进行柯里化
if (fn.length > newArgs.length) {
// fn.length获取了参数的数量
return curry(fn, newArgs);
} else {
return fn.apply(this, newArgs);
}
};
}
es6装逼版本
const curry = fn =>
judge = (...args) =>
fn.length > args.length
? (...newArg) => judge(...args, ...newArg)
: fn(...args);
6、事件分发器EventEmitter
Node.js 所有的异步 I/O 操作在完成时都会发送一个事件到事件队列。
Node.js 里面的许多对象都会分发事件:一个 net.Server 对象会在每次有新连接时触发一个事件, 一个 fs.readStream 对象会在文件被打开的时候触发一个事件。 所有这些产生事件的对象都是 events.EventEmitter 的实例。
实现一个简单的 EventEmitter 类,需要实现 once, on, off, emit 方法
once表示该类型的事件只触发一次就删除on表示挂载一个类型的事件off表示卸载一个类型的事件emit表示对某一类型的事件进行一次分发
我还把别人的改了一下,他原版的有问题,不过我估计他思路应该是对的,就是实际写的时候漏了一下,还是表示敬佩。
class EventEmitter {
constructor() {
this.handlers = {};
}
// 注册事件回调
on(eventName, cb) {
const handlers = this.handlers;
if (!handlers[eventName]) {
handlers[eventName] = [];
}
handlers[eventName].push(cb);
}
// 移除某个事件回调队列中的事件回调函数
off(eventName, cb) {
const callbacks = this.handlers[eventName];
if (!callbacks) return;
const idx = callbacks.indexOf(cb);
if (idx !== -1) {
callbacks.splice(idx, 1);
}
}
// 触发某类事件中注册的所有回调
emit(eventName, ...args) {
const callbacks = this.handlers[eventName];
if (callbacks) {
// 对事件队列做一次浅拷贝,主要是防止 once 注册的回调在触发后对调用顺序造成影响
const _callbacks = callbacks.slice();
_callbacks.forEach((cb) => {
cb(...args);
});
}
}
once(eventName, cb) {
const wrappedCb = (...args) => {
cb(...args);
this.off(eventName, wrappedCb);
};
this.on(eventName, wrappedCb);
}
}
7、JSONP
在前端面试中,JSONP 绝对是一个非常非常重要的知识点,一般情况下不会直接让写代码,更多的是口头描述,但要描述清楚需要对 JSONP 的写法非常熟悉。
JSONP 即 JSON with Padding。它是借助了 HTML 中 src 属性可跨域的特点来进行 GET 请求,我们通过 src 中 url 部分的参数传递,给出回调的函数名,如 ?callback=cbFunction,然后响应中返回要执行的 JS 代码,使用字符串拼接的方式传递回调函数中的参数,然后浏览器接受响应,就直接执行了返回的代码。
因此 JSONP 由两部分组成:回调函数 和 数据。回调函数是当响应到来时要在页面中调用的函数,函数名一般通过请求 url 传递;而数据通过服务器响应请求时通过字符串拼接作为回调函数的参数返回。
JSONP 优点:
- 不受同源策略的限制
- 兼容性好
- 实现简单
缺点:
- 只支持
GET请求 - 属于嵌入式脚本,有一定安全风险
简便的写法
function jsonp({url, callbackName, callback}) {
let script = document.createElement('script');
callbackName = callbackName || 'randomName';
let newURL = `${url}?jsoncallback=${callbackName}`;
script.src = newURL;
document.body.appendChild(script);
window[callbackName] = callback;
}
jsonp({
url: 'https://www.runoob.com/try/ajax/jsonp.php',
callback: (data) => {console.log(data)},
// callbackName: 'callbackFunc'
});
这个麻瓜一点的版本,不过确实这个能够处理异步的请求,也算是还可以吧
const chars = 'abcdefghijklmnopqrstuvwxyz';
function randomString(strs, length) {
let str = '';
for (let i = 0; i < length; ++i) {
str += strs[Math.floor(Math.random() * strs.length)];
}
return str;
}
const jsonp = ({ url, params, callbackName }) => {
const generateURL = () => {
let str = `jsoncallback=${callbackName}`;
if (params) {
str += Object.keys(params)
.map((key) => `${key}=${params[key]}`)
.join('&');
}
return `${url}?${str}`;
};
return new Promise((resolve, reject) => {
callbackName = callbackName || randomString(chars, 10);
let scriptEle = document.createElement('script');
scriptEle.src = generateURL();
document.body.appendChild(scriptEle);
// 服务器返回字符串 'callbackName(data)',浏览器解析即可执行
// 在全局对象中添加处理回调方法
window[callbackName] = (data) => {
resolve(data);
// 最后再移除不需要的 dom 节点,防止内存泄漏
document.body.removeChild(scriptEle);
};
});
};
// 实例,使用菜鸟教程中提供的接口调用 jsonp 方法
jsonp({
url: 'https://www.runoob.com/try/ajax/jsonp.php',
callbackName: 'callbackFunction'
}).then((data) => {
console.log(data);
});
8、原生方法实现
instancof
instanceof 运算符用于检测构造函数的 prototype 属性是否出现在实例对象的原型链上。
(错误的理解:instanceof检测对象是某一个函数构造器创建)
(正确的理解:instanceof检测右边的函数原型是否存在于左边对象的原型链上)
故:instanceof 操作符其实就是检查左侧的元素的 proto 链上有没有右侧类或对象的 prototype存在。因此实现思路就是顺着原型链逐层查找,直到原型链的尽头 null 为止,若过程中 left 的原型与 right 的原型相同,则返回 true。
function myInstanceOf(left, right) {
// 如果对象不存在并且不是object实例对象,false
if (!left || typeof left !== 'object') return false;
// 获得左边的原型
let proto = Object.getPrototypeOf(left);
while (true) {
if (proto === null) return false;
if (proto === right.prototype) return true;
proto = Object.getPrototypeOf(proto);
}
}
a instanceof Foo更好的表示可以用Foo.prototype.isPrototypeOf(a)
Object.create
创建一个纯净的新对象,然后继承其原型
当然还有那些判断,可以加上去
//Object.prototype.myCreate = function (proto) {
Object.myCreate = function (proto) {
//这里应该用静态方法,而不是原型链
if (typeof proto !== 'object' && typeof proto !== 'function') {
throw new TypeError('Object prototype may only be an Object: ' + proto);
} else if (proto === null) {
throw new Error("This browser's implementation of Object.create is a shim and doesn't support 'null' as the first argument.");
}
// 创建一个空函数并将其 prototype 指向 proto
function F() {}
F.prototype = proto;
// 返回一个新的实例对象,这样实例对象就能够访问到 proto 及其原型链上的属性和方法了
return new F();
};
new
new 被调用后做了几件事:
- 创建一个空对象
- 将新对象的[[Prototype]]指针指向构造函数的prototype属性
- 将新创建的对象作为this的上下文(新创建的对象就是this)
- 如果函数内部返回一个对象,那么就将该对象作为整个表达式的值返回,而传入构造函数的this将被丢弃(之前新创建的对象就被废弃)
- 但如果不是对象,比如返回数字,那么忽略返回值,会返回新创建的对象
- 如果该函数没有返回对象,则返回新创建的对象
function myNew(constructor, ...args) {
if (typeof constructor !== 'function') throw `${constructor} is not a constructor`;
const obj = Object.create(constructor.prototype); // 1/2、创建一个新的对象,并继承其原型
const res = constructor.apply(obj, args); // 3、执行上下文
return typeof res === 'object' ? res : obj; //返回对象,有对象,返回对象
}
注意:上述的new和Object.create不要一起使用,因为new里面包含Object.create,而Object.create包含new。如果想要一个完全没有Object.create的new实现,参考下面的代码,摘抄自《JavaScript设计模式与开发实践》。但这个方法并不是完美的,需要借助对象的__proto__属性,这并非是JavaScript正式的用法,这属性是隐藏的,只是浏览器把这个属性给暴露出来了,所以这种方法也不是完美的使用。说到底new方法或者Object.create有一个必须要通过底层引擎来实现,而不能利用代码完美替换。
var objectFactory = function(){
const obj = new Object(); //从Object.prototype上克隆的一个空对象
const Constructor = [].shift.call(arguments); //取得外部传入的构造器,比如objectFactory(构造器,'参数')这样子。
obj.__proto__ = Constructor.prototype; // 这一块其实就是Object.create的核心了,目的就是把当前对象的内部属性__proto__指向构造器的原型对象
const res = Constructor.apply(obj,arguments); //借用外部传入的构造器给obj设置属性
return typeof res === 'object' ? res : obj;
}
call&apply
call 方法的作用和 apply 方法类似,区别仅是 call 方法接受的是参数列表,而 apply 方法接受的是一个参数数组。
它们的作用都是使用指定的上下文来调用函数,若有传入额外的参数,那么该参数会传递给调用函数。
Function.prototype.myCall = function () {
// apply 同写法
if (typeof this !== 'function') throw `caller must be a function!`;
const context = arguments[0] || window; // 上下文属性,如果没有就是window了
const args = [...arguments].slice(1).flat(); // 对于 apply 的话,传入的是一个参数数组,因此将参数格式统一
context.fn = this; // 这里有点抽象了,把当前发起调用的函数作为上下文(对象)的其中一个函数,这样子这个fn里面的this指向就是context,而context就是指定的对象
const res = context.fn(...args); // 并且执行这个函数
delete context.fn; // 然后在上下文中删除这个函数
return res;
};
bind
bind 方法会创建一个新函数,然后会将传入的上下文对象绑定到调用函数上。若传递了多个参数,其余参数会作为新函数的参数。此外,若是对使用了 bind 绑定的函数使用了 new 关键字创建实例对象,那么此时会忽略原先传入的上下文对象。
Function.prototype.myBind = function () {
if (typeof this !== 'function') throw new TypeError('caller must be a function');
// 函数为当前调用者
const fn = this;
// 下上文
const context = arguments[0];
// 传进来的参数作为新函数的参数
const args = Array.prototype.slice.call(arguments, 1);
const bindFunc = function () {
//当然这个新传进来的参数放在新函数的前面还是后面我不知道
const newArgs = args.concat(Array.from(arguments));
// 若是普通情况,this 会指向 window,而若是使用 new ,那么 this 会指向实例
return fn.apply(this instanceof bindFunc ? this : context, newArgs);
};
// bindFunc 继承原型链中的方法
bindFunc.prototype = Object.create(fn.prototype);
return bindFunc;
};
不过需要注意的是,对于原生 bind 方法来说,返回的新函数是没有 prototype 属性的,而上面自己实现的方法显然会带有 prototype。
Array.prototype.map
map 概念:
map(callback(val, idx, arr), thisArg) 方法将创建一个新数组,这个数组中的元素是原数组中的每个元素都调用 callback 后的结果。其中 callback 的三个参数分别是原数组中的元素、元素对应索引值和原数组,thisArg 可选,是 map 函数的 this 指向。
因此调用 map 函数后,原数组不会发生改变。
此外,调用的数组 arr 中的元素不一定是连续的(有的索引位置会为 empty),这点需要注意。
Array.prototype.myMap = function (callbackFn, thisArg) {
// null 或 undefined
if (this == null) {
throw new TypeError(`can't not read proterty 'map' of ${this}`);
}
// 为啥不用typeof
if (Object.prototype.toString.call(callbackFn) !== '[object Function]') {
throw new TypeError(`${callbackFn} is not a function!`);
}
let obj = Object(this); // 规定 this 需要先转换为对象
let len = obj.length >>> 0; // 保证 len 为数字且为整数
// 这里为啥不是 thisArg|| this;
let _this = thisArg || null;
let res = new Array(len);
for (let i = 0; i < len; ++i) {
if (i in obj) {
// 这一步对应数组中某些为empty的情况
let mappedValue = callbackFn.call(_this, obj[i], i, obj);
res[i] = mappedValue;
}
}
return res;
};
Array.prototype.flat
flat(deep)方法会根据指定的递归深度遍历数组,并将遍历到的元素合并为一个新数组返回
不传参数的情况下,默认扁平化一层。当传入Infinity时,无论多少,都会转换为一维数组。传入参数小于0,则不进行任何扁平化操作。若数组不是连续的,则会跳过那些。
原版又错了,真有他的,每次弄完不测试一下的嘛???
Array.prototype.myFlat = function (deep = 1) {
if (deep > 0) {
const arr = this.reduce((preVal, curVal) => {
if (Array.isArray(curVal)) {
return [...preVal, ...curVal.myFlat(deep - 1)];
}
return [...preVal, curVal];
}, []);
return arr;
} else {
return this;
}
};
还有不想弄了,感觉目前用处不大了
class
这里不实现类,而是讲讲class的语法糖的写法对应着原本函数写法的什么样子
class Ninja {
constructor(name, level = 0) {
// 这是局部变量,不能被外部所修改(除开闭包)
let i = 0;
// 实例属性
this.name = name;
this.level = level;
// 实例方法
this.sayName = () => {
console.log(this.name);
};
// 给this赋值的,都是实例成员
}
// 原型方法(定义在类块中的方法会作为原型方法)
swingSword() {
return true;
}
/**
那么就会有一个问题,实例有属性和方法,那么原型能不能也有属性呢?
答案是否定的,不能在类块中给原型添加原始值或者对象作为成员数据!
但在TypeScript中能够实现!!(注意:这里说的是类块里面不能实现!!)
*/
// 也可以和普通对象一样设置访问器
set name(newName) {
this.name = newName;
}
get name() {
return this.name;
}
// 静态方法
static compare(ninja1, ninja2) {
return ninja1.level - ninja2.level;
}
//
}
// 虽然不能在类块内添加成员数据,但在类定义外部手动添加
// 这里应该指的是类似静态属性的东西?
Ninja.greeting = '空你急哇';
// 在原型上定义数据成员
Ninja.prototype.swingSword = 'Yoshi';
// 之所以没有显式支持添加数据成员,是因为在共享目标上(原型和类)上添加可变
// (可修改)数据成员是一种反模式,一般来说,数据成员应该通过this添加到实例上
9、继承
1、通过构造函数来继承
通过构造函数来继承,就是在子类中借用父类的构造函数,传入自己的 this 来继承属性。
缺点:只能继承父类中定义的实例属性,而不能继承原型中的属性。方法都在构造函数中定义,每次创建实例都会创建一遍方法。
function Parent() {}
function Child() {
Parent.call(this);
}
2、通过原型链来继承
通过原型链来继承,将子类的原型指向父类的实例对象,由此继承父类原型中的属性和方法。这种继承方式的缺点是在子类实例化了多个对象时,若从父类继承的属性中有引用类型的对象,那么对这个对象内容的修改会反映到其他实例对象上,因为这些属性都是从一个 __proto__ 中继承而来的。
function Parent() {
this.list = [1, 2, 3];
}
function Child() {}
// 通过修改原型来实现继承
Child.prototype = new Parent();
Child.prototype.constructor = Child;
/** 其实最好用Object.defineProperty来定义,因为constructor是不可被枚举的
Object.defineProperty(Child.prototype,"constructor",{
enumerable: false,
value: Child,
writable:true
})
**/
// 子类申明了两个实例对象
let c1 = new Child();
let c2 = new Child();
c1.list.push(4); // c1 的修改在 c2 中也会生效,因为是从 __proto__ 中继承来的
c2.list; // [1, 2, 3, 4]
3、组合继承
也就是组合上面两种方式即使用父类构造函数并通过原型链继承的方式来达到继承的效果。这种方式的缺点是需要调用两次构造函数,并且继承的属性会存在冗余(即 Child 继承了属性,而原型中也有对应属性)。
function Parent() {
this.a = 1;
}
function Child() {
Parent.call(this);
}
Child.prototype = new Parent();
Child.prototype.constructor = Child;
const c = new Child();
4、寄生继承
寄生继承是通过一个中间对象来创建一个新对象,并在这个新对象上能做某些增强,比如添加属性或方法。
这种方法的缺点是:跟借用构造函数模式一样,每次创建对象都会创建一遍方法。
const obj = {
list: [1, 2, 3],
name: 'yle'
};
// 这个就是Object.create()方法,而且这种方式叫做原型式继承
function createObject(o) {
function F() {}
F.prototype = o;
return new F();
}
function createAnother(origin) {
const newObj = createObject(origin);
newObj.hello = function() {
console.log('hello');
};
return newObj;
}
const o = createAnother(obj);
const o1 = createAnother(obj);
o1.list.push(4); // 改动会作用到 o 中,因为原型的指向是一样的
console.log(o.list); // [1,2,3,4]
5、组合寄生继承
这种继承方式通过借用父类构造函数与原型链来继承属性和方法,它避免了组合继承方式中调用父类构造函数两次的缺点。具体实现就是在子类中调用父类构造函数并传入自身 this,然后将其prototype 通过一个中间对象来指向父类的原型。
不必为了指定子类的原型而调用超类构造函数,我们只需超类的原型副本即可。即使用寄生式继承来继承超类原型,然后将结果(实例)指定给子类原型。
function Parent() {}
function Child() {
Parent.call(this);
}
// 这边的 Object.create 相当于上面寄生继承中的 createObject,这是ES5的语法,缺点就是会抛弃掉默认的Child.prototype对象,不能直接修改已有的默认对象,有一点轻微的垃圾回收问题
Child.prototype = Object.create(Parent.prototype);
// ES6的语法,可以借助setPrototypeOf直接修改现有的Child.prototype,更好
// Object.setPrototypeOf(Child.prototype,Parent.prototype);
Child.prototype.constructor = Child;
// 若想更为完备的话,可再使用 setPrototypeOf 方法来使得子类能够继承父类的静态属性和静态方法(这句话存疑)
// Object.setPrototypeOf(Child, Parent);
10、图片懒加载
懒加载是一种网页性能优化策略,若一个页面中当前不可见区域有图片需要加载,那么可以延迟该图片的请求,直到达到该图片的可视区域为止。
懒加载实现原理
网页中一般占用较多资源的是图片文件,因此懒加载一般是针对图片而言的。
而一张图片就是一个 <img> 标签,图片的加载源就是其 src 属性,浏览器发起请求就是根据其是否有 src 属性来决定的。
因此可以根据 <img> 标签的位置,当标签在可视区域之外时,其 src 属性为空,而当即将进入可视区域时,设置其 src 属性,让浏览器发起图片请求。
所以说懒加载的要点就是可视区域的判断。
懒加载会在页面进行滚动时调用判断函数,因此需要进行节流优化。
首先,用一幅图解释浏览器的宽高:
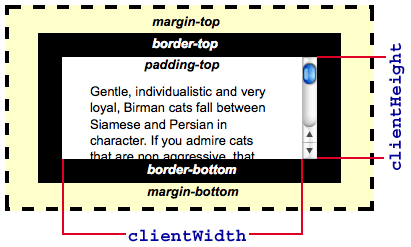
方法一、clientHeight、scrollTop 和 offsetTop
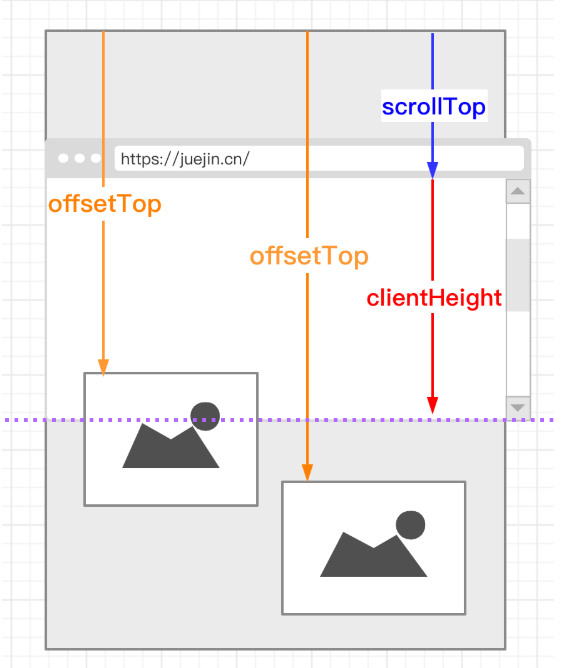
HTMLElement.offsetTop为只读属性,它返回当前元素相对于其offsetParent元素的顶部内边距的距离。
Element.scrollTop属性可以获取或设置一个元素的内容垂直滚动的像素数。
HTMLElement.clientHeight对于没有定义CSS或者内联布局盒子的元素为0,否则,它是元素内部的高度(单位像素),包含内边距,但不包括水平滚动条、边框和外边距。
clientHeight可以通过 CSSheight+ CSSpadding- 水平滚动条高度 (如果存在)来计算。
clientHeight可以使用window.innerHeight来替代 ,不过若有水平滚动条,innerHeight也会包括滚动条高度。
document.documentElement总是会返回一个html元素,且它一定是该文档的根元素。
那么由上图可知,页面的高度为 clientHeight,若有滚轮的话,scrollTop 会是当前页面滚动的高度,而 offsetTop 会是元素距离页面顶部的高度。
因此当 scrollTop + clientHeight = offsetTop 时,就说明元素即将进入可视区域,图片需要进行请求了(确实是这样子的)
function getTop(e) {
let T = e.offsetTop;
while (e = e.offsetParent) {
T += e.offsetTop;
}
return T;
}
function lazyLoad(imgs) {
// 视口高度
const viewHeight = document.documentElement.clientHeight;
// 滚动条拉伸的高度
const scrollTop = document.documentElement.scrollTop || document.body.scrollTop;
// 这么拉?还要遍历?我以为多厉害,没事了,原来有个count,会实时记录已经加载的长度,这样子就会从未加载的开始,也不是不行。
for (let i = count; i < imgs.length; ++i) {
if (getTop(imgs[i]) <= viewHeight + scrollTop) {
if (!imgs[i].getAttribute('src')) {
// 图片的 url 放在 data-src 属性中(有趣)
imgs[i].src = imgs[i].getAttribute('data-src');
count++; // count 值用于减少循环开销
}
}
}
}
方法二、getBoundingClientRect
Element.getBoundingClientRect()方法返回元素的大小及其相对于视口的位置。如果是标准盒子模型,元素的尺寸等于
width/height+padding+border-width的总和。如果box-sizing: border-box,元素的的尺寸等于width/height。返回的结果是包含完整元素的最小矩形,并且拥有
left,top,right,bottom,x,y,width, 和height这几个以像素为单位的只读属性用于描述整个边框。除了width和height以外的属性是相对于视图窗口的左上角来计算的。
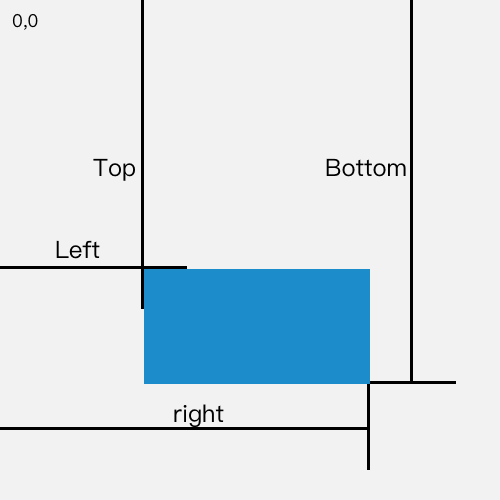
因此使用 DOM 元素的 getBoundingClientReact().top 属性就能直接判断图片是否出现在了当前视口中。
function lazyLoad(imgs) {
let viewHeight = document.documentElement.clientHeight;
for (let i = count; i < imgs.length; ++i) {
if (imgs[i].getBoundingClientRect().top <= viewHeight) {
if (!imgs[i].getAttribute('src')) {
imgs[i].src = imgs[i].getAttribute('data-src');
count++;
}
}
}
}
方法三、浏览器 API IntersectionObserver
IntersectionObserver 浏览器内置的 API,实现了监听 window 的 scroll 事件、判断是否在视口中 以及 节流 三大功能。chrome51开始支持。
下面的代码中:
- 传入的回调函数的
changes是IntersectionObserverEntry对象的数组,数组中的每个对象的target是实际可视情况发生改变的dom元素。 getElementsByTagName返回的是一个HTMLCollection,因此需要使用Array.from来转换一下。
const imgs = document.getElementsByTagName('img');
const observer = new IntersectionObserver((changes) => {
changes.forEach(dom => {
if (dom.isIntersecting) {
dom.target.src = dom.target.getAttribute('data-src');
// 当加载后就从监视器中移除
observer.unobserve(dom.target);
}
});
});
Array.from(imgs).forEach(dom => observer.observe(dom));
其他方法
-
使用开源库如 https://github.com/aFarkas/lazysizes (滑稽
-
使用 html5 新特性(未实操过),新的API,在chrome77才支持,edge则是79,safari则是到15.4还是实验性质,还没有正式支持。
<img src="image.jpg" alt="..." loading="lazy"> <iframe src="video-player.html" title="..." loading="lazy"></iframe>
实例
<head>
<style>
body {
height: 3000px;
}
img {
width: 500px;
height: 500px;
object-fit: scale-down;
}
</style>
</head>
<body>
<img data-src="./imgs/1.png">
<img data-src="./imgs/2.png">
<img data-src="./imgs/3.png">
<img data-src="./imgs/4.png">
<img data-src="./imgs/5.png">
<img data-src="./imgs/6.png">
<img data-src="./imgs/7.png">
<img data-src="./imgs/8.png">
<script>
// 方法1:clientHeight、scrollTop、offsetTop
let imgs = document.getElementsByTagName('img'), count = 0;
// offsetTop 是元素与 offsetParent 的距离,循环获取直到达到页面顶部
function getTop(e) {
let T = e.offsetTop;
while (e = e.offsetParent) {
T += e.offsetTop;
}
return T;
}
function lazyLoad(imgs) {
// 视口高度
let viewHeight = document.documentElement.clientHeight;
// 滚动条拉伸的高度
let scrollTop = document.documentElement.scrollTop || document.body.scrollTop ;
for (let i = count; i < imgs.length; ++i) {
if (getTop(imgs[i]) <= viewHeight + scrollTop) {
if (!imgs[i].getAttribute('src')) {
imgs[i].src = imgs[i].getAttribute('data-src');
count++;
}
}
}
}
function throttle(fn, wait, ...args) {
let activeTime = 0;
return function() {
let current = +new Date();
if (wait <= current - activeTime) {
fn.apply(this, args.concat(...arguments));
activeTime = current;
}
};
}
// 首次加载
window.onload = lazyLoad(imgs);
window.onscroll = throttle(lazyLoad, 100, imgs);
</script>
</body>
上面介绍的前三种方法,其中前两种方法是有一定缺陷的,它们只比较了距离页面顶端的距离,因此若刷新浏览器时,所处位置的上方所有可见和不可见的图片都会被加载出来,因此并不是完备的懒加载。
不过第三种使用 IntersectionObserver 的方法则不会有这个问题,它的弱势是观察器在进程中的优先级会比较低且需要考虑兼容性问题。
11、箭头函数
和普通函数的区别
- 没有单独this
- 不绑定arguments
- 不能使用super和new.target
- 不能用作构造函数
- 也没有prototype
虽然箭头函数不能作为构造函数,但是它自己是有构造函数的(所有引用对象都有[[Prototype]],但是只有函数对象有prototype)。但是箭头函数没有prototype,所以不能被当做构造函数来new(因为 new的有一个步骤是将空对象的[[Prototype]]链接到函数对象的prototype,箭头函数没有,所以这一步就直接死了)




